
前言
在上一篇文章 《面试官不讲武德》对Java初级程序猿死命摩擦Http协议 中,我们有提到大文件下载和断点续传,本篇我们就来开发一个多线程文件下载器,最后我们用这个多线程下载器来突破百度云盘下载的限速。
兄弟们看到这个标题可能会觉得是个标题党,为了解决疑虑,我们先来看下最终的测试结果:
测试百度云下载的文件 46M,自己本地最大下载速度 2M
1. 单线程下载,总耗时: 603s

2. 多线程下载,50个线程,总耗时:13s

测试结果,提速46倍,我还是太谦虚了,只说提速30倍,此处我们觉得应该有掌声(我听不到,还是点赞实在)

源码地址: https://gitee.com/silently9527/fast-download
喜欢请记得star哦
HTTP协议Range请求头
Range主要是针对只需要获取部分资源的范围请求,通过指定Range即可告知服务器资源的指定范围。格式: Range: bytes=start-end
比如: 获取字节范围 5001-10000
Range: bytes=5001-10000也可以指定开始位置不指定结束位置,表示获取开始位置之后的全部数据
Range: bytes=5001-服务器接收到带有Range的请求,会在处理请求之后返回状态码为206 Partial Content的响应。
基于Range的特性,我们就可以实现文件的多线程下载,文件的断点续传
准备工作
本文我们使用的SpringMVC中的RestTemplate;由于百度云的链接是Https,所以我们需要设置RestTemplate绕过证书验证
- pom.xml

- 编写
RestTemplate的构造器,以及绕过https的证书验证

- 在下载的过程中,我们需要知道当前下载的速度是多少,所以需要定义一个显示下载速度的接口

因为计算下载速度,我们需要知道每秒传输的字节数是多少,为了监控传输数据的过程,我们需要了解SpringMVC中的接口ResponseExtractor
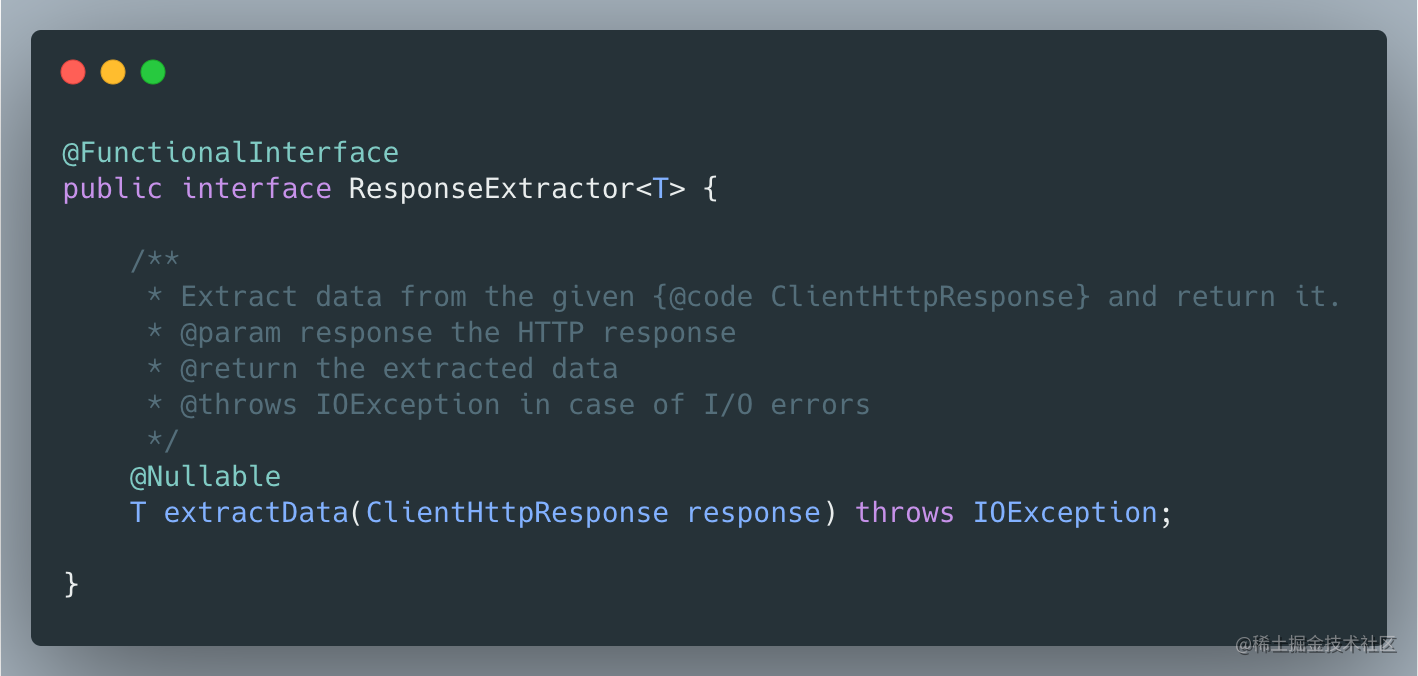
该接口只有一个方法,当客户端和服务器端连接建立之后,会调用这个方法,我们可以在这个方法中监控下载的速度。
DisplayDownloadSpeed接口的抽象实现AbstractDisplayDownloadSpeedResponseExtractor

- 整个项目主要涉及到的类图
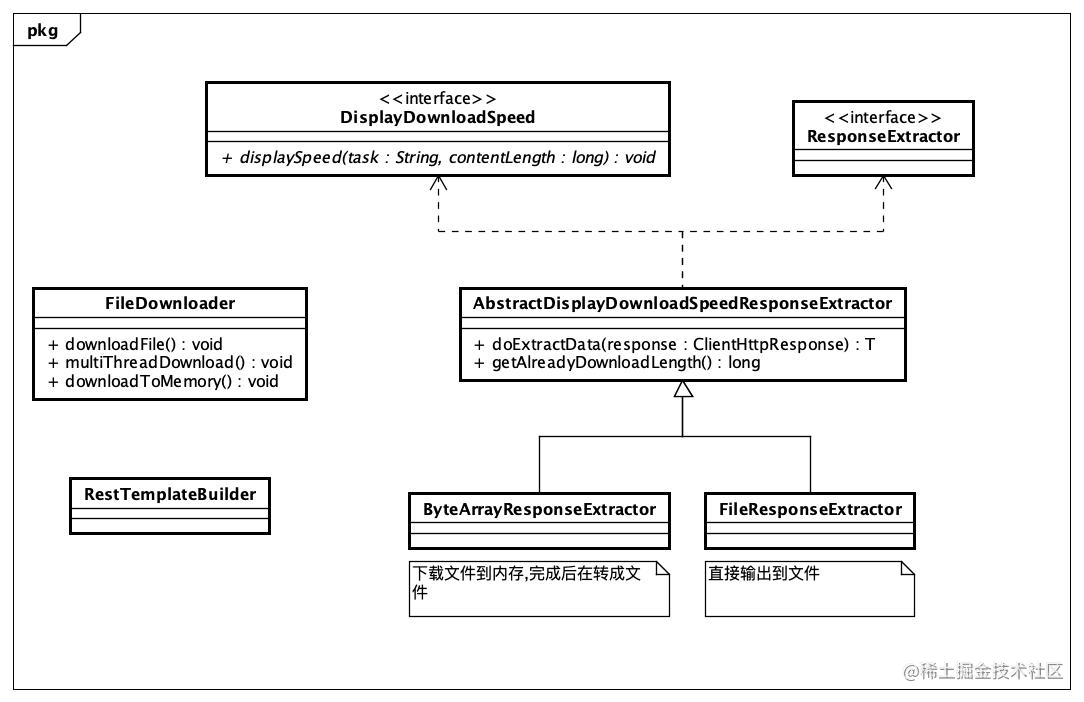
简单的文件下载器
这里使用的是restTemplate调用execute, 先文件获取到字节数组, 再将字节数组直接写到目标文件。
这里我们需要注意的点是: 这种方式会将文件的字节数组全部放入内存中, 及其消耗资源;我们来看看如何实现。
- 创建
ByteArrayResponseExtractor类继承AbstractDisplayDownloadSpeedResponseExtractor

- 调用
restTemplate.execute执行下载,保存字节数据到文件中

- 测试下载819M的idea

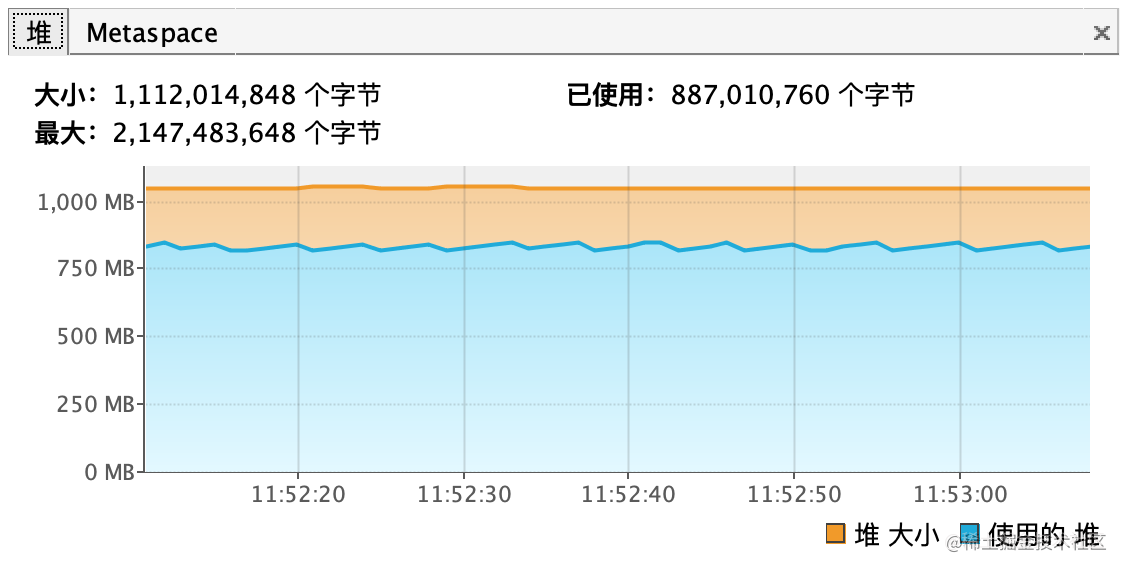
执行一段时间之后,我们可以看到内存已经使用了800M左右,所以这种方式只能使用于小文件的下载,如果我们下载几G的大文件,内存肯定是不够用的。至于下载时间,因为文件太大也没有等下载完成就结束了程序。
单线程大文件下载
上面的方式只能下载小的文件,那大文件的下载我们该用什么方式呢?我们可以把流输出到文件而不是内存中。接下来我们来实现我们大文件的下载。
- 创建
FileResponseExtractor类继承AbstractDisplayDownloadSpeedResponseExtractor,把流输出到文件中

- 文件下载器,先把流输出到临时下载文件(xxxxx.download),下载完成后在重命名文件

- 测试下载819M的idea
执行一段时间之后,我们再看看下内存的使用情况,发现这种方式内存消耗较少,效果比较理想,下载时间:199s


多线程文件下载
如果服务器不限速的话,通常能够把自己本地的带宽给跑满,那么使用单线程下载就够了,但是如果遇到服务器限速,下载速度远小于自己本地的带宽,那么可以考虑使用多线程下载。多线程我们使用CompletableFuture(可以参考文章 CompletableFuture让你的代码免受阻塞之苦)。
实现多线程文件下载的基本流程:
- 首先我们通过Http协议的Head方法获取到文件的总大小
- 然后根据设置的线程数均分文件的大小,计算每个线程的下载的字节数据开始位置和结束位置
- 开启线程,设置HTTP请求头Range信息,开始下载数据到临时文件
- 下载完成后把每个线程下载完成的临时文件合并成一个文件
完成代码如下:

- 开启30个线程测试下载819M的idea



从执行的结果上来看,因为开启了30个线程同时在下载,内存的占用要比单线程消耗的多,但是也在接受范围内,下载时间:81s,速度提升2.5倍,这是因为idea的下载服务器没有限速,本次多线程速度的提升仅仅是在充分的压榨本地的带宽,所以提示的幅度不大。
单线程下载和对线程下载对比测试
因为百度云盘对单个线程的下载速度做了限制,大概是在100kb,所以我们使用百度云盘的下载链接,来测试多线程和单线程的下载速度。
测试 百度云盘中 46M 的文件的下载速度,自己本地最大下载速度 2M
获取文件的下载地址

注意:从浏览器中获取的链接需要先使用URLDecode解码,否则下载会失败,并且百度云盘文件的下载链接是有时效性的,过期后就不能在下载,需要重新生成下载链接
测试单线程下载文件
执行的结果可以看出,百度云对单线程的下载限速真的是丧心病狂, 46M的文件下载需要耗时: 600s
测试多线程下载文件
为了充分的压榨网速,找出最合适的线程数,所以测试了不同线程数的下载速度
| 线程数 | 下载总耗时 |
|---|---|
| 10 | 60s |
| 20 | 30s |
| 30 | 21s |
| 40 | 15s |
| 50 | 13s |
从测试的结果上来看,对于自己的运行环境把线程数设置在30个左右比较合适
文件断点续传如何实现,欢迎在大家评论区说出自己的思路。