
Agrona提供了环形缓冲区工具类,本篇主要从基本使用和源码的角度来学习OneToOneRingBuffer、ManyToOneRingBuffer
OneToOneRingBuffer 使用
1. 写入数据write
缓存区的大小是预先定义的并且不能修改,在下面的示例中,底层缓冲区是在堆外分配的,并设置为接受 4096 字节的内容。需要添加RingBufferDescriptor.TRAILER_LENGTH,以便支持环形缓冲区的数据保存在同一底层缓冲区中。请注意,通过写入环形缓冲区的任何数据write都会附带一个额外的 8 字节标头,因此在调整底层缓冲区大小时一定要记住这一开销。
final int bufferLength = 4096 + RingBufferDescriptor.TRAILER_LENGTH;
final UnsafeBuffer internalBuffer
= new UnsafeBuffer(ByteBuffer.allocateDirect(bufferLength));
final OneToOneRingBuffer ringBuffer
= new OneToOneRingBuffer(internalBuffer);其中的RingBufferDescriptor.TRAILER_LENGTH 以及 为何write的数据需要额外写 8 字节在后续的源码分析中解答。
发送数据非常简单,调用write方法即可,返回值指示写入是否成功,如果值为false,则写入失败
//prepare some data
final UnsafeBuffer toSend = new UnsafeBuffer(ByteBuffer.allocateDirect(10));
toSend.putStringWithoutLengthAscii(0, "012345679");
//write the data
private sentOk = ringBuffer.write(1, toSend, 0, 10);2. tryClaim
在上面调用write方法写入数据时我们可以发现需要提前声明一个Buffer,在写入数据的时候会多产生一次数据的拷贝;在性能要求高的场景下我们可以考虑使用 tryClaim , 允许我们直接写入底层的Buffer达到减少数据拷贝的目的。
final RingBuffer ringBuffer = ...;
final int index = ringBuffer.tryClaim(msgTypeId, messageLength);
if (index > 0) {
try {
final AtomicBuffer buffer = ringBuffer.buffer();
// 用户之间操作底层的buffer来写入数据
...
ringBuffer.commit(index); // commit message
}
catch (final Exception ex) {
ringBuffer.abort(index); // allow consumer to proceed
...
} finally {
ringBuffer.commit(index); // commit message
}
}- 首先调用tryClaim申请写入数据的空间,如果返回的索引 > 0,说明空间足够,可以从这个索引的位置开始写入数据。
- 然后我们继续获取底层缓冲区的对象,通过这个对象写入数据
buffer.put - 最后,commit或abort
3. 读取数据 read、controlledRead
数据的使用是通过 agrona 接口的实现完成的 MessageHandler,例如:
class MessageCapture implements MessageHandler
{
@Override
public void onMessage(int msgTypeId, MutableDirectBuffer buffer, int index, int length)
{
//do something
}
}当我们在读取消息的是,可能会根据消息的内容来控制是否需要跳过本条消息等操作,需要实现接口ControlledMessageHandler
class ControlledMessageCapture implements ControlledMessageHandler{
@Override
public ControlledMessageHandler.Action onMessage(int msgTypeId, MutableDirectBuffer buffer, int index, int length)
{
..do something
return Action.COMMIT; //or ABORT, BREAK OR CONTINUE as required.
}
}该接口的返回值是返回值的类型ControlledMessageHandler.Action, 有 4 个选项:
- ABORT: 消息的head指针将会重新回到本条消息的开头,然后break读取消息的while循环;等待下一次调用read从新消费该消息
- BREAK: break读取消息的while循环;等待下一次调用read从新消费该消息
- COMMIT: 该消息读取有效,更新head指针的位置
- CONTINUE: 继续读取,直到读取连续空间的所有消息或者超过了允许读取的最大消息条数;这个类型的效果等同于调用read
可以通过RingBuffer对象的方法监视缓冲区的生产者和消费者进度。
//the current consumer position in the ring buffer
ringBuffer.consumerPosition();
//the current producer position in the ring buffer
ringBuffer.producerPosition();OneToOneRingBuffer 源码
1. RecordDescriptor
在上文有提到写入到buffer中的数据都会多8个字节,是由于agrona在写入每条消息的时候会添加头信息(MsgTypeId、MsgLength)

- MsgLength: 消息的长度,占用4个字节
- MsgTypeId: 消息的类型,占用4个字节,
- Message: 实际消息的内容
消息头信息的定义在RecordDescriptor中, 主要使用的方法:
public static int typeOffset(final int recordOffset){
return recordOffset + SIZE_OF_INT;
}
public static int lengthOffset(final int recordOffset){
return recordOffset;
}
public static int encodedMsgOffset(final int recordOffset){
return recordOffset + HEADER_LENGTH;
}- lengthOffset: 消息长度在buffer中的offset
- typeOffset: 消息类型在buffer中的offset
- encodedMsgOffset: 实际消息内容在buffer中的offset
2. 核心指针(RingBufferDescriptor)
在开始分析源码之前我们先来看看这张图
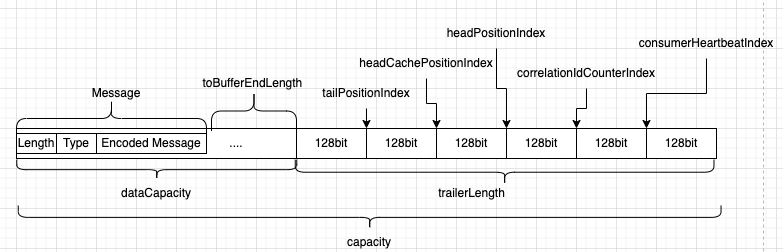
在前面使用OneToOneRingBuffer的例子中,申请缓冲区空间的时候需要预留出TRAILER_LENGTH
final int bufferLength = 4096 + RingBufferDescriptor.TRAILER_LENGTH;从图上我们可以看到 capacity = dataCapacity + trailerLength, OneToOneRingBuffer会在构造方法中计算出实际存放数据大小的空间dataCapacity,checkCapacity方法返回的就是dataCapacity;dataCapacity中存放的就是每条消息
public static int checkCapacity(final int capacity, final int minCapacity)
{
final int dataCapacity = capacity - TRAILER_LENGTH;
...
return dataCapacity;
}trailerLength主要是用来记录RingBuffer的指针信息,这些指针的偏移量定义在RingBufferDescriptor, 其中最重要的有三个:
- tailPositionIndex: 存放尾部指针,用来计算下条消息写入的位置,这个值会一直增加,计算实际的写入index = tail & mask
- headCachePositionIndex: 存放缓存的头指针,在write的时候,当计算出来的可用空间不够时会读取headPositionIndex中的值来更新为最新的head位置
if (requiredCapacity > availableCapacity){
head = buffer.getLongVolatile(headPositionIndex);
if (requiredCapacity > (capacity - (int)(tail - head))){
return INSUFFICIENT_CAPACITY;
}
buffer.putLong(headCachePositionIndex, head);
}- headPositionIndex: 存放实际的head指针,再读取消息的时候会更新到最新位置
注意:tailPositionIndex、headPositionIndex以及headCachePositionIndex的值是固定的,在创建OneToOneRingBuffer就设置好了,它们是用来存放head和tail的,注意不要和head、tail混淆
3. write方法
在写入数据的时候最核心的方法就是claimCapacity,用来申请空间写入数据,这里我们就主要看claimCapacity是如何来申请空间的,首先我们需要说明以下几个变量方便后续源码阅读
- tail: 尾部指针,一直累加写入消息length,写入的时候更新
- head: 头部指针,一直累加读取消息length,读取的时候更新
- requiredCapacity: 写入消息需要的空间
- toBufferEndLength: buffer剩余的连续空间(注意看上面的图)
- availableCapacity: buffer允许写入的可用空间
capacity - (int)(tail - head) - writeIndex: 申请的空间开始写入的位置
在知道了上面的几个参数之后继续来看看claimCapacity的方法,主要处理了三种情况:
3.1 requiredCapacity < toBufferEndLength
表示剩余空间充足,足够写入的消息,直接更新tailPositionIndex,然后返回允许写入的writeIndex
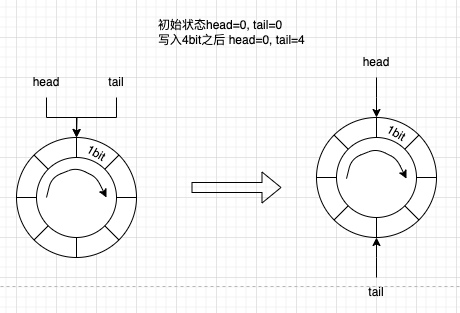
注意图例每个格子表示1bit,图例只是展示head,tail指针变化的过程,不考虑消息的头信息
final long tail = buffer.getLong(tailPositionIndex);
long nextTail = tail + alignedRecordLength;
buffer.putLongOrdered(tailPositionIndex, nextTail);
final int recordIndex = (int)tail & mask;
if (alignedRecordLength == toBufferEndLength) {
buffer.putLongOrdered(tailPositionIndex, nextTail);
buffer.putLong(0, 0L); // pre-zero next message header
return recordIndex;
}3.2 alignedRecordLength == toBufferEndLength
表示剩余的空间刚好够写入消息
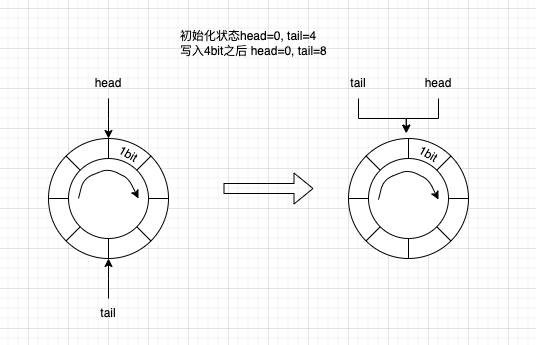
if (alignedRecordLength == toBufferEndLength){
buffer.putLongOrdered(tailPositionIndex, nextTail);
buffer.putLong(0, 0L); // pre-zero next message header
return recordIndex;
}3.3 requiredCapacity > toBufferEndLength
表示剩余的空间不足写入本条消息,那么剩余的空间会填充, 保证写入数据是在连续的空间中,方便读取与写入; 设置writeInde=0, 更新nextTail 填充消息的类型PADDING_MSG_TYPE_ID(=-1), 填充的消息长度等于toBufferEndLength,在读取的时候就使用这两个值跳过填充类型的消息。 由于是从数组的开头写入,所以还需要判断需要申请的空间大小与headIndex比较,如果可写入的空间不够就返回 -2
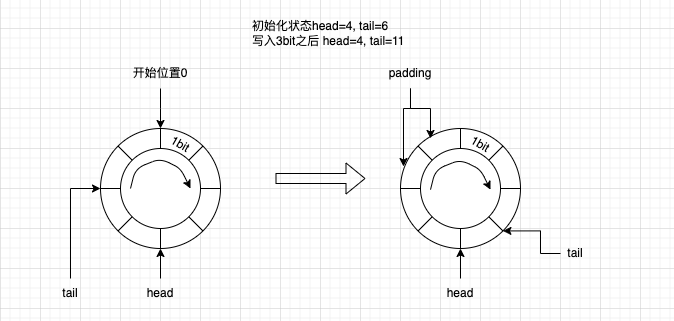
if (requiredCapacity > toBufferEndLength){
writeIndex = 0;
int headIndex = (int)head & mask;
if (requiredCapacity > headIndex) { //判断空间是否足够
head = buffer.getLongVolatile(headPositionIndex);
headIndex = (int)head & mask;
if (requiredCapacity > headIndex) {
writeIndex = INSUFFICIENT_CAPACITY;
nextTail = tail;
}
buffer.putLong(headCachePositionIndex, head);
}
padding = toBufferEndLength;
nextTail += padding;
}
if (0 != padding) {
buffer.putLong(0, 0L);
buffer.putIntOrdered(lengthOffset(recordIndex), -padding);
MemoryAccess.releaseFence();
buffer.putInt(typeOffset(recordIndex), PADDING_MSG_TYPE_ID); //设置填充的消息类型
buffer.putIntOrdered(lengthOffset(recordIndex), padding); //设置填充的消息长度
}
return writeIndex;到此claimCapacity方法的主要逻辑就结束了。
3.4 申请需要的写入空间之后 write方法中写入消息类型,消息长度,消息内容
buffer.putBytes(encodedMsgOffset(recordIndex), srcBuffer, offset, length);
buffer.putInt(typeOffset(recordIndex), msgTypeId);
buffer.putIntOrdered(lengthOffset(recordIndex), recordLength);3. tryClaim方法
- 同write方法一样先调用
claimCapacity方法去申请写入的空间 - 空间申请成功后 只写入消息的类型与消息长度的负数
-recordLength - 返回了实际消息的写入位置
tryClaim方法允许我们可以直接操作底层的缓冲区,不用像write方法一样需要多做一次拷贝
public int tryClaim(final int msgTypeId, final int length){
checkTypeId(msgTypeId);
checkMsgLength(length);
final AtomicBuffer buffer = this.buffer;
final int recordLength = length + HEADER_LENGTH;
final int recordIndex = claimCapacity(buffer, recordLength);
if (INSUFFICIENT_CAPACITY == recordIndex){
return recordIndex;
}
buffer.putIntOrdered(lengthOffset(recordIndex), -recordLength);
MemoryAccess.releaseFence();
buffer.putInt(typeOffset(recordIndex), msgTypeId);
return encodedMsgOffset(recordIndex);
}4. commit方法
主要逻辑就是修改消息的长度,在tryClaim中写入的长度是原本消息长度的负数,在commit中修正成正确的长度
public void commit(final int index){
final int recordIndex = computeRecordIndex(index);
final AtomicBuffer buffer = this.buffer;
final int recordLength = verifyClaimedSpaceNotReleased(buffer, recordIndex);
buffer.putIntOrdered(lengthOffset(recordIndex), -recordLength);
}5. abort方法
把在tryClaim中写入的消息类型覆盖成PADDING_MSG_TYPE_ID,在tryClaim中写入的长度是原本消息长度的负数,这里修改成正数,这样本次消息写入的数据将会作废,在读取的时候会直接跳过
public void abort(final int index){
final int recordIndex = computeRecordIndex(index);
final AtomicBuffer buffer = this.buffer;
final int recordLength = verifyClaimedSpaceNotReleased(buffer, recordIndex);
buffer.putInt(typeOffset(recordIndex), PADDING_MSG_TYPE_ID);
buffer.putIntOrdered(lengthOffset(recordIndex), -recordLength);
}6. read方法
- 从head的位置开始 循环顺序解读每一条消息(msgLength, msgTypeId, message)
- 解读出消息后 调用
MessageHandler.onMessage处理消息 - 在读取数据的时候可能会遇到填充的数据
msgType=PADDING_MSG_TYPE_ID, 直接跳过这种类型的消息 - 循环结束条件:读取的总字节数>=允许读取的连续空间
contiguousBlockLength=capacity - headIndex或者已经读取的消息数 > 设置的最大值 - finally中更新headPositionIndex到最新位置
try {
while ((bytesRead < contiguousBlockLength) && (messagesRead < messageCountLimit)) {
final int recordIndex = headIndex + bytesRead;
final int recordLength = buffer.getIntVolatile(lengthOffset(recordIndex));
if (recordLength <= 0) {
break;
}
bytesRead += align(recordLength, ALIGNMENT);
final int messageTypeId = buffer.getInt(typeOffset(recordIndex));
if (PADDING_MSG_TYPE_ID == messageTypeId) {
continue;
}
handler.onMessage(messageTypeId, buffer, recordIndex + HEADER_LENGTH, recordLength - HEADER_LENGTH);
++messagesRead;
}
}finally {
if (bytesRead > 0) {
buffer.putLongOrdered(headPositionIndex, head + bytesRead);
}
}接下来继续看看controlledRead的返回值ControlledMessageHandler.Action,ControlledMessageHandler.Action在之前的使用部分已经讲过。
try{
while ((bytesRead < contiguousBlockLength) && (messagesRead < messageCountLimit)) {
...
final ControlledMessageHandler.Action action = handler.onMessage(messageTypeId, buffer, recordIndex + HEADER_LENGTH, recordLength - HEADER_LENGTH);
if (ABORT == action) {
bytesRead -= alignedLength;
break;
}
++messagesRead;
if (BREAK == action) {
break;
}
if (COMMIT == action) {
buffer.putLongOrdered(headPositionIndex, head + bytesRead);
headIndex += bytesRead;
head += bytesRead;
bytesRead = 0;
}
}
}finally {
if (bytesRead > 0) {
buffer.putLongOrdered(headPositionIndex, head + bytesRead);
}
}最后 ManyToOneRingBuffer使用和源码与 OneyToOneRingBuffer 基本一致,源码有一点需要关注的就是 ManyToOneRingBuffer允许多个producer写入数据,所以在更新tailPositionIndex的时候使用cas更新
do
{
...
}
while (!buffer.compareAndSetLong(tailPositionIndex, tail, newTail));