
在Java7之前想要并行处理大量数据是很困难的,首先把数据拆分成很多个部分,然后把这这些子部分放入到每个线程中去执行计算逻辑,最后在把每个线程返回的计算结果进行合并操作;在Java7中提供了一个处理大数据的fork/join框架,屏蔽掉了线程之间交互的处理,更加专注于数据的处理。
Fork/Join框架
Fork/Join框架采用的是思想就是分而治之,把大的任务拆分成小的任务,然后放入到独立的线程中去计算,同时为了最大限度的利用多核CPU,采用了一个种工作窃取的算法来运行任务,也就是说当某个线程处理完自己工作队列中的任务后,尝试当其他线程的工作队列中窃取一个任务来执行,直到所有任务处理完毕。所以为了减少线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行;在百度找了一张图
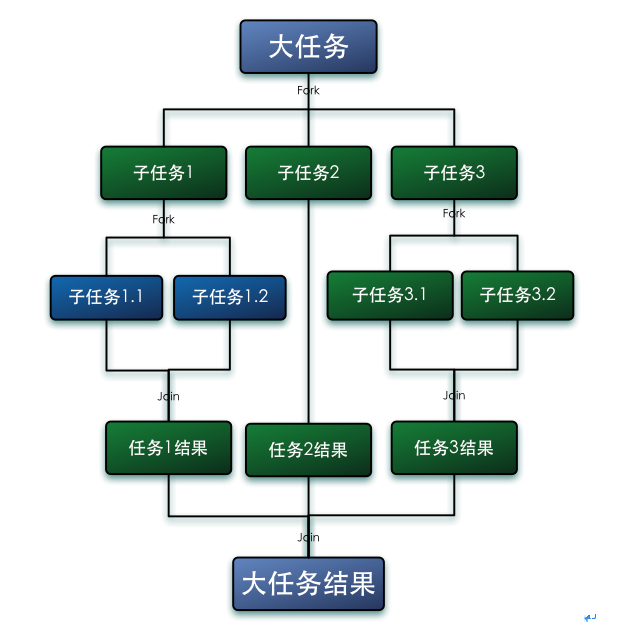
- 使用
RecursiveTask使用Fork/Join框架首先需要创建自己的任务,需要继承RecursiveTask,实现抽象方法
protected abstract V compute();实现类需要在该方法中实现任务的拆分,计算,合并;伪代码可以表示成这样:
if(任务已经不可拆分){
return 顺序计算结果;
} else {
1.任务拆分成两个子任务
2.递归调用本方法,拆分子任务
3.等待子任务执行完成
4.合并子任务的结果
}- Fork/Join实战
任务:完成对一亿个自然数求和
我们先使用串行的方式实现,代码如下:
long result = LongStream.rangeClosed(1, 100000000)
.reduce(0, Long::sum);
System.out.println("result:" + result);使用Fork/Join框架实现,代码如下:
public class SumRecursiveTask extends RecursiveTask<Long> {
private long[] numbers;
private int start;
private int end;
public SumRecursiveTask(long[] numbers) {
this.numbers = numbers;
this.start = 0;
this.end = numbers.length;
}
public SumRecursiveTask(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
int length = end - start;
if (length < 20000) { //小于20000个就不在进行拆分
return sum();
}
SumRecursiveTask leftTask = new SumRecursiveTask(numbers, start, start + length / 2); //进行任务拆分
SumRecursiveTask rightTask = new SumRecursiveTask(numbers, start + (length / 2), end); //进行任务拆分
leftTask.fork(); //把该子任务交友ForkJoinPoll线程池去执行
rightTask.fork(); //把该子任务交友ForkJoinPoll线程池去执行
return leftTask.join() + rightTask.join(); //把子任务的结果相加
}
private long sum() {
int sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 100000000).toArray();
Long result = new ForkJoinPool().invoke(new SumRecursiveTask(numbers));
System.out.println("result:" +result);
}
}Fork/Join默认的线程数量就是你的处理器数量,这个值是由
Runtime.getRuntime().available- Processors()得到的。 但是你可以通过系统属性java.util.concurrent.ForkJoinPool.common. parallelism来改变线程池大小,如下所示:System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");这是一个全局设置,因此它将影响代码中所有的并行流。目前还无法专为某个 并行流指定这个值。因为会影响到所有的并行流,所以在任务中经历避免网络/IO操作,否则可能会拖慢其他并行流的运行速度
parallelStream
以上我们说到的都是在Java7中使用并行流的操作,Java8并没有止步于此,为我们提供更加便利的方式,那就是parallelStream;parallelStream底层还是通过Fork/Join框架来实现的。
- 常见的使用方式 1.串行流转化成并行流
LongStream.rangeClosed(1,1000)
.parallel()
.forEach(System.out::println);2.直接生成并行流
List<Integer> values = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
values.add(i);
}
values.parallelStream()
.forEach(System.out::println);- 正确的使用parallelStream
我们使用parallelStream来实现上面的累加例子看看效果,代码如下:
public static void main(String[] args) {
Summer summer = new Summer();
LongStream.rangeClosed(1, 100000000)
.parallel()
.forEach(summer::add);
System.out.println("result:" + summer.sum);
}
static class Summer {
public long sum = 0;
public void add(long value) {
sum += value;
}
}运行结果如下:
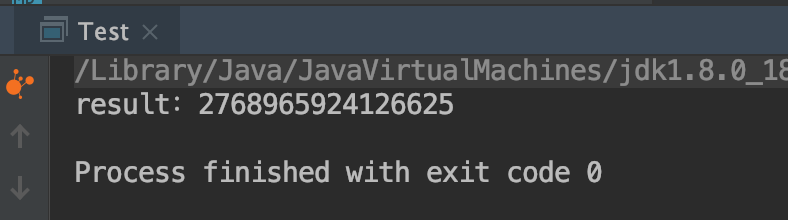
运行之后,我们发现运行的结果不正确,并且每次运行的结果都不一样,这是为什么呢? 这里其实就是错用parallelStream常见的情况,parallelStream是非线程安全的,在这个里面中使用多个线程去修改了共享变量sum, 执行了sum += value操作,这个操作本身是非原子性的,所以在使用并行流时应该避免去修改共享变量。
修改上面的例子,正确使用parallelStream来实现,代码如下:
long result = LongStream.rangeClosed(1, 100000000)
.parallel()
.reduce(0, Long::sum);
System.out.println("result:" + result);在前面我们已经说过了fork/join的操作流程是:拆子部分,计算,合并结果;因为parallelStream底层使用的也是fork/join框架,所以这些步骤也是需要做的,但是从上面的代码,我们看到Long::sum做了计算,reduce做了合并结果,我们并没有去做任务的拆分,所以这个过程肯定是parallelStream已经帮我们实现了,这个时候就必须的说说Spliterator
Spliterator是Java8加入的新接口,是为了并行执行任务而设计的。
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}tryAdvance: 遍历所有的元素,如果还有可以遍历的就返回ture,否则返回false
trySplit: 对所有的元素进行拆分成小的子部分,如果已经不能拆分就返回null
estimateSize: 当前拆分里面还剩余多少个元素
characteristics: 返回当前Spliterator特性集的编码
总结
- 要证明并行处理比顺序处理效率高,只能通过测试,不能靠猜测(本文累加的例子在多台电脑上运行了多次,也并不能证明采用并行来处理累加就一定比串行的快多少,所以只能通过多测试,环境不同可能结果就会不同)
- 数据量较少,并且计算逻辑简单,通常不建议使用并行流
- 需要考虑流的操作时间消耗
- 在有些情况下需要自己去实现拆分的逻辑,并行流才能高效
感谢大家可以耐心地读到这里。 当然,文中或许会存在或多或少的不足、错误之处,有建议或者意见也非常欢迎大家在评论交流。 最后,希望朋友们可以点赞评论关注三连,因为这些就是我分享的全部动力来源🙏