
跳跃列表
zset 内部的排序功能是通过「跳跃列表」数据结构来实现的,因为 zset 要支持随机的插入和删除,所以它不好使用数组来实现,

先来看看普通的链表需要按照score值进行排序,所以在插入的时候,需要定位到正确的位置,这样才能保证链表有序。通常我们会通过二分法找到插入点,但是二分法只能是数组,普通的链表没有办法使用二分法。 这时候就需要使用到跳跃列表,

上图就是跳跃列表的示意图,图中只画了四层,Redis 的跳跃表共有 64 层,意味着最多可以容纳 2^64 次方个元素。最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。
查找过程
设想如果跳跃列表只有一层会怎样?插入删除操作需要定位到相应的位置节点 (定位到最后一个比「我」小的元素,也就是第一个比「我」大的元素的前一个),定位的效率肯定比较差,复杂度将会是 O(n),因为需要挨个遍历。也许你会想到二分查找,但是二分查找的结构只能是有序数组。跳跃列表有了多层结构之后,这个定位的算法复杂度将会降到O(lg(n))。
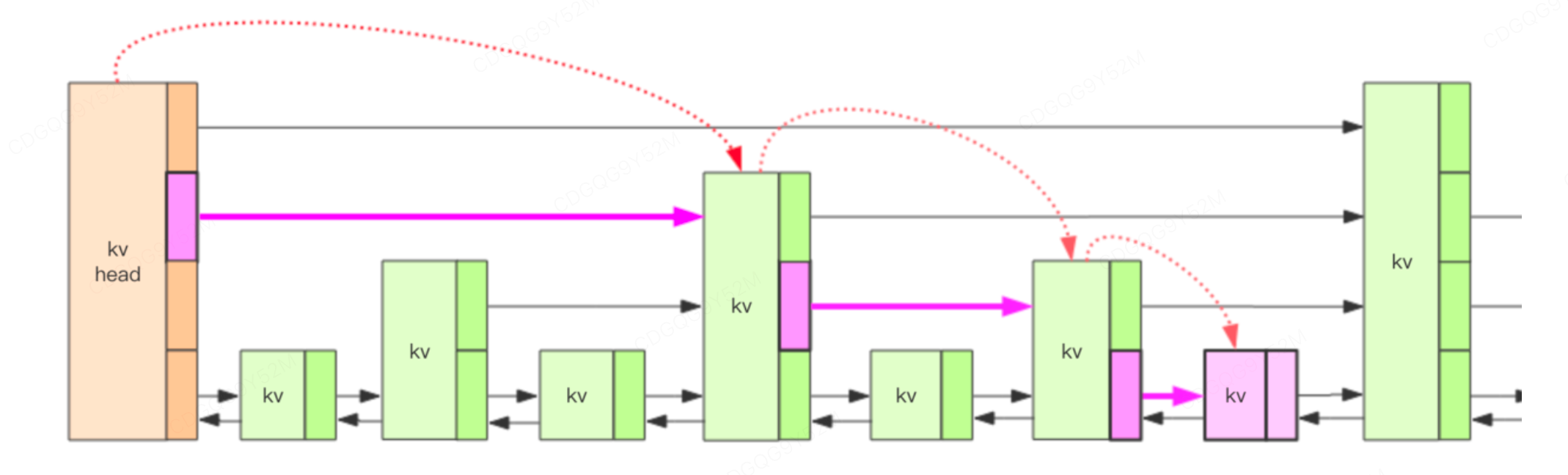
如图所示,我们要定位到那个紫色的 kv,需要从 header 的最高层开始遍历找到第一个节点 (最后一个比「我」小的元素),然后从这个节点开始降一层再遍历找到第二个节点 (最后一个比「我」小的元素),然后一直降到最底层进行遍历就找到了期望的节点 (最底层的最后一个比我「小」的元素)。
随机层数
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数。首先 L0 层肯定是 100% 了,L1 层只有 50% 的概率,L2 层只有 25% 的概率,L3层只有 12.5% 的概率,一直随机到最顶层 L64 层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。
原文链接: http://herman7z.site