
Scan 指令
在工作中经常需要使用模糊查询某个Key,redis提供了 keys 指令,如果redis中存储几百万的key,这个指令就会严重影响redis性能;所以redis提供了 scan 指令, 特性:
- 复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程;
- 提供 limit 参数,可以控制每次返回结果的最大条数,limit 只是一个 hint,返回的结果可多可少;
- 同 keys 一样,它也提供模式匹配功能;
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
- 返回的结果可能会有重复,需要客户端去重复,这点非常重要;
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零;
指令: scan [cursor] match [key] count [number]
- cursor: 整数值,scan指令的结果会返回cursor
- key: 查询的key,支持正则模式
- number: 指定扫描多少个slot
eg: scan 0 match key99* count 1000
字典的结构
在redis中所有的key都存放在一张很大的哈希表中,结构与Java中的HashMap结构一样, 数组的大小是 2^n, 每次扩容是扩容原来的2倍。scan指令返回的cursor就是数组的位置索引(slot)。
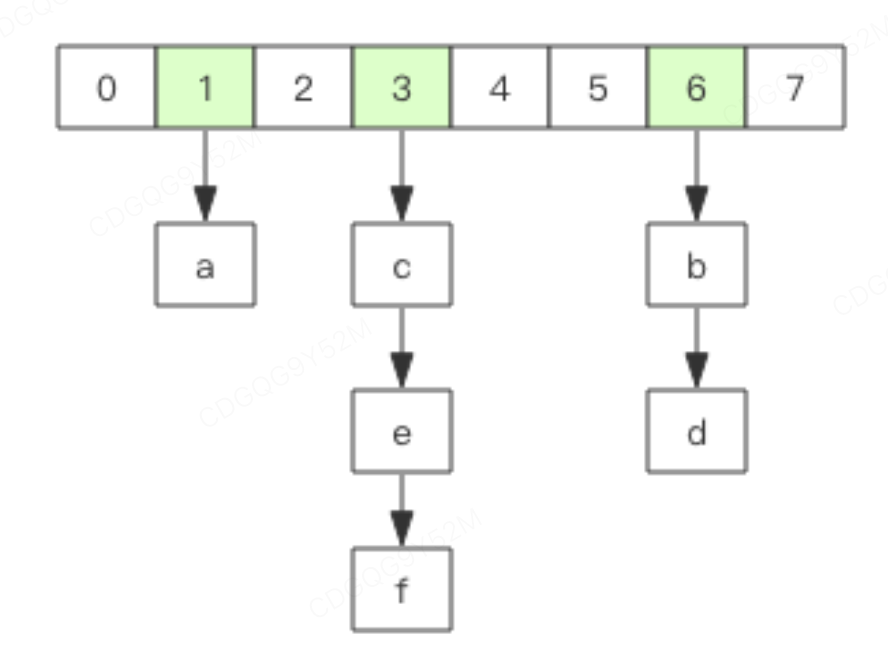
字典扩容
哈希字典的扩容过程和Java中HashMap的方式相同,当 loadFactor 达到阈值时,需要重新分配一个新的 2 倍大小的数组,然后将所有的元素全部 rehash 挂到新的数组下面。rehash 就是将元素的 hash 值对数组长度进行取模运算,因为长度变了,所以每个元素挂接的槽位可能也发生了变化。又因为数组的长度是 2^n 次方,所以取模运算等价于位与操作。 当进行扩容的时候,原来slot下链表的全部元素会被拆分成两个链表,一个链表依旧放到原来的slot,一个链表会放到 oldCapacity + oldIndex;
举例:原始数组大小8,存在两个元素hashCode是1和9;那么计算出来这两个元素都会被存放在slot=1的位置,因为 1 = (8-1)&1 =(8-1)&9; 扩容的时候数组大小变成16, (16-1)&1 = 1 , (16-1)&9 = 9
scan遍历顺序
scan 的遍历顺序非常特别。它不是从第一维数组的第 0 位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
普通加法和高位进位加法的区别: 高位进位法从左边加,进位往右边移动,同普通加法正好相反。但是最终它们都会遍历所有的槽位并且没有重复。
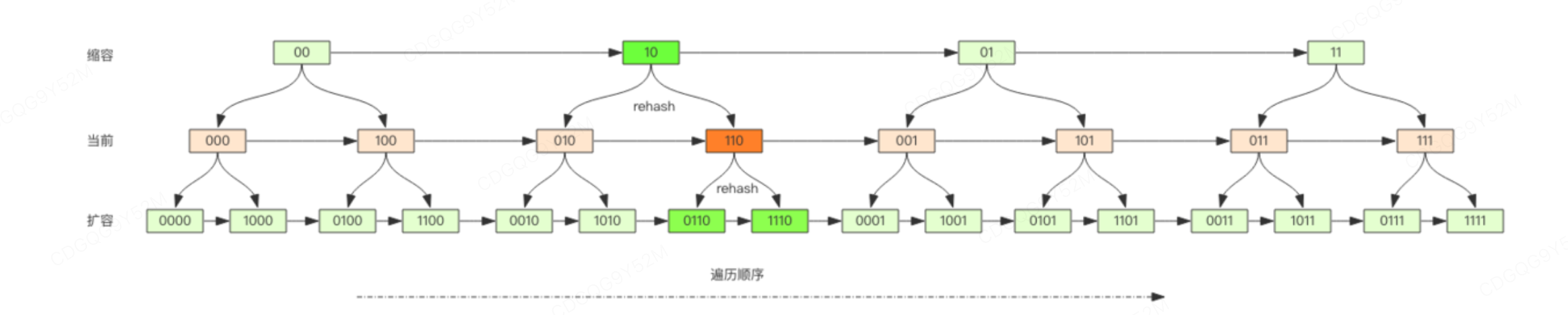
观察这张图,我们发现采用高位进位加法的遍历顺序,rehash 后的槽位在遍历顺序上是相邻的。这样就可以避免扩容后对已经遍历过的槽位进行重复遍历
原文链接: http://herman7z.site