
学习完前面两篇文章之后,我们知道了innodb的数据页组成了一个双向链表,而每个数据页中的记录会按照主键的大小顺序组成一个条单向链表。 数据页还会为对所有的记录进行分组,提取组内的最后一条的位置信息组成页目录,这样在页内通过id查询的时候就可以使用二分法快速的查找到需要的记录。
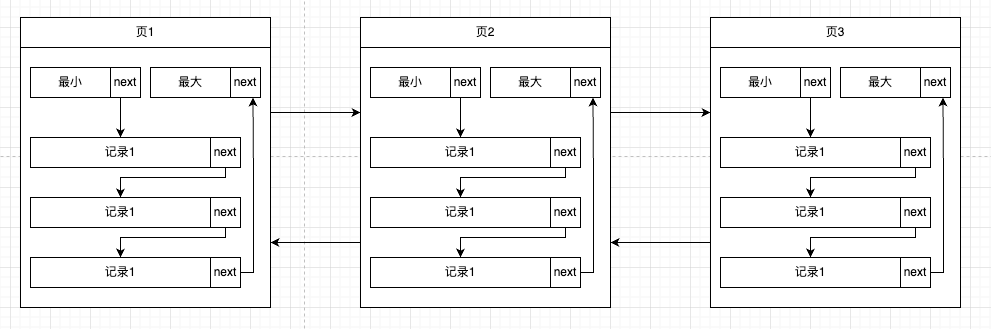
问题:
- 如果表数量很大,innodb会把数据存放在很多页中,通过id查询的时候,如何能够快速定位数据在哪一页呢?
- 如果不通过表中的其他字段查询数据,如何能够快速定位数据的位置呢?
简单的索引方案
这里我们可以参考innodb页目录的设计思路来设计一个简单的索引,在开始之前我们先来简化一下行记录,只关注索引相关的字段

- record_type: 表示记录的类型, 0:普通用户记录,1:索引目录项,2:infimum记录,3:supremum记录
- next_record: 指向下一条记录
- 剩余的表示真实数据列的值
接着我们把记录竖这放,只关心record_type、next_record、以及用户真实数据,那么数据页的展示如下:
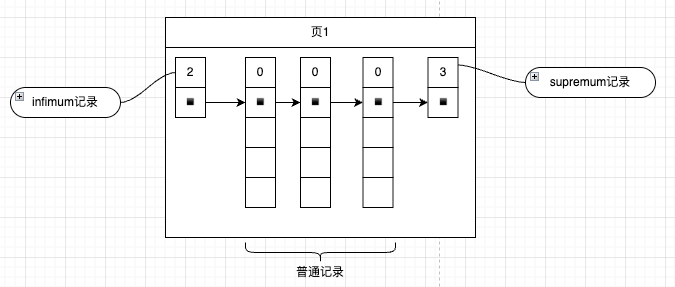
接着来考虑下因为如何来建立索引,这里可以参考innodb目录页的设计,为所有的页面构建一个目录,使用二分法就可以快速查询,为了实现这个目录,需要做两个事情:
- 数据页内的数据主键必须从小到达的顺序排列(已实现), 数据页之间必须是下页的主键id必须大于上一页的主键id
为了实现这个目的需要在插入数据的时候就需要检查保证顺序, 如果原来的数据页1已经满了,这时候需要申请新的数据页2,把数据页1中大于插入记录id的数据移动到页2中,把需要插入的数据放入到页面1,这个过程就是页分裂
页分裂会影响插入的性能,所以我们在设置表主键的时候尽量选择自增类型的id
假如我们每个页只能存三条数据,那么我们插入一些数据之后的数据页的结果
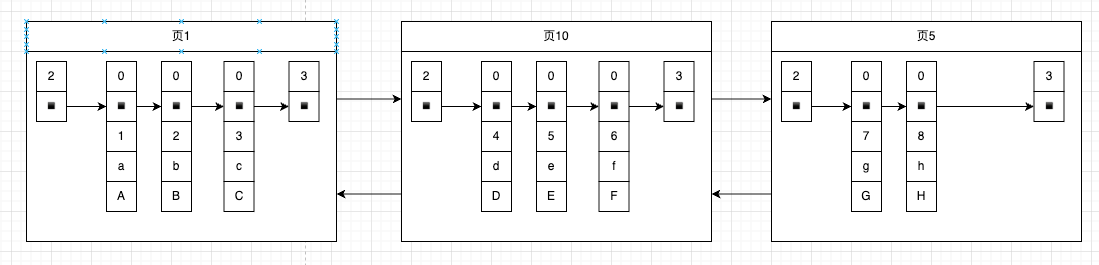
数据页可能是连续,也可能不是连续的,在磁盘上可能并不相连,所以数据页面之间使用链表链接的
- 为数据页建立目录项
每个页对应一个目录项,每个目录项中包含两字段:
- 页内第一条记录的id,也就是最小的id
- 页号
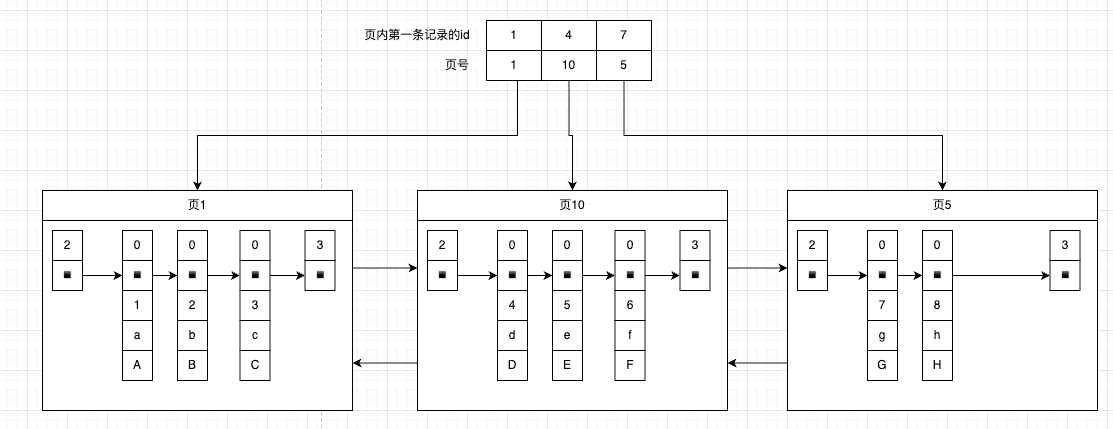
假如我们需要查询id=5的记录:
- 先查询目录,使用二分法查询到数据在 页10 中
- 在使用之前我们提到的在页内查找数据的方法即可快速查到 记录id=5
这就是一个简易版本的索引,来看看我们设计的索引有什么问题:
- 我们的索引目录项需要存放在连续的地址空间中,当表中的数据非常大的时候,会出现很多的数据页面,这就需要很大的连续空间才能够存放全部的目录项
- 当一个数据页中的数据全部都被删除的时候,那么这个目录项也不再需要了,删除目录项后需要把后面的全部都向前移动一位,这个操作不好。
innodb中的索引方案
innodb直接使用的数据页来存储的目录项,目录项中的两个字段:记录主键id、页号,这两个字段当成了一条记录写入到了user records中
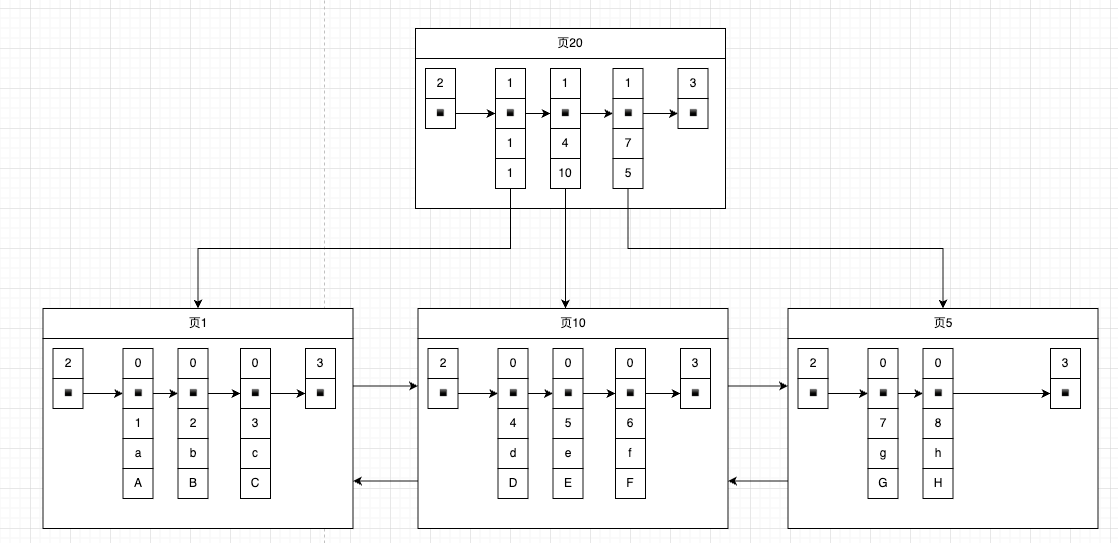
- 目录项中record_type 设置成了 1
- 目录项中的记录只有主键id和页号
这时候我们查询id=5的记录的步骤:
- 在索引页30中查找,这个与查询普通用户数据一样,使用 二分法 在页目录中查找
- 找到记录所在的页面10之后,在到 页面10 中使用 二分法 在页目录中查找
当前数据少我们只使用到了一个索引页,一个页面只有16KB,当表中的数据很大的时候,一个页面不足存储全部的索引,所以当插入数据时索引页满了就执行页分裂, 这时候索引页面就有两个,还需要再对这两个索引页面建立索引页,最终效果如图:
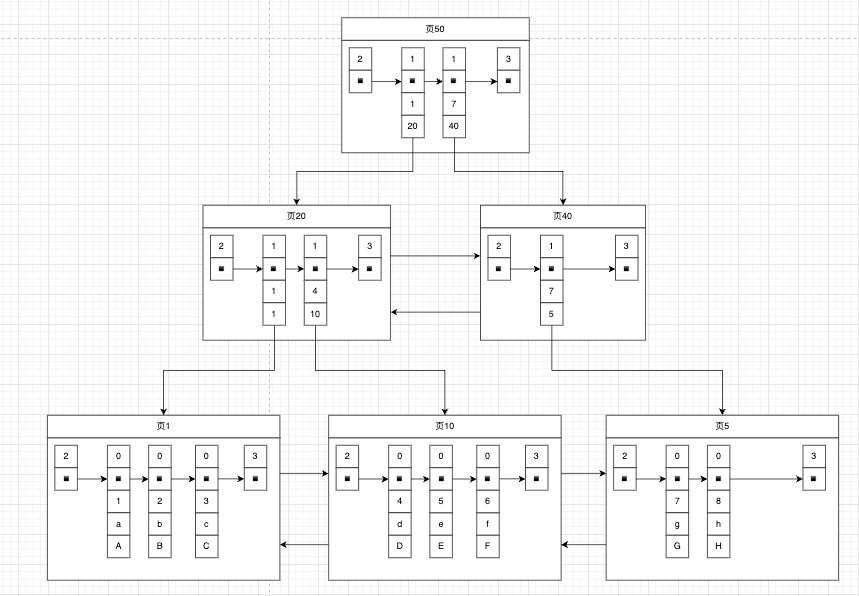
- 为了简洁,假如索引页面只能存放最多两条数据,所以分页出了 页面20,页面40
- 为页面20,页面40建立索引页50
这就是B+树,无论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把他们存在了B+树的数据结构中。这些数据页就是B+数的节点,只有叶子节点会存放用户的记录, 非叶子节点存放目录项记录,最顶部节点就是根节点。
假如一个数据页能存放用户的记录100条,能存放目录项记录1000条,那么:
- 如果B+树只有1层,能存放 100 条数据
- 如果B+树只有2层,能存放 100 * 1000 条数据
- 如果B+树只有3层,能存放 100 * 1000 * 1000 条数据
- 如果B+树只有4层,能存放 100 * 1000 * 1000 * 1000 条数据
所以一般情况下,B+树的层级不会超过4层,这样一来通过主键id查询只需要查4个页面就能够找到数据。
在PageHeader中 有个字段page_level,这个就记录了当前页在B+树中的层级
聚簇索引
- 使用记录的主键值的大小进行记录和页的排序;
- B+树的叶子节点记存储的是完整的用户记录(用户记录的所有列数据)
innodb会自动为我们聚簇索引,聚簇索引就是Innodb引擎存储数据的方式。
二级索引
由于聚簇索引只支持通过id查询数据,如果需要通过表中的其他字段查询数据就没办法快速查询,比如 字段 a,这时候就需要为 字段a 创建一个二级索引。 二级索引与聚簇索引类似,仅有几处不同:
- 使用 字段a 作为页内记录与数据页之间的排序,而不是使用主键;
- 数据页内,记录通过字段a的大小顺序组成一个单向链表,然后分组提取组长构成页目录,页内查询使用二分法快速定位字段a的所在记录的位置。
- 数据页之间,通过字段a的大小顺序组成一个双向链表
- 存放目录项记录的索引页分为不同的层级,同一层级的索引页也是通过 字段a 的大小顺序组成双向链表
- B+树的叶子节点不存储用户记录完整数据,只存储 字段a 和记录的主键 两列
- 目录项记录中不在是主键 + 页号,而是字段a+页面号
联合索引
使用多个字段作为索引列,这种叫做联合索引,比如字段a,字段b
- 先把各个记录和页按照字段a进行排序
- 如果字段a相同,就按照字段b进行排序
- B+树非叶子节点目录项使用字段a,字段b,页号组成。
- B+树的叶子节点中的用户记录存储的 字段a,字段b,主键 组成
原文链接: http://herman7z.site