
布隆过滤器使用
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
- bf.add: 添加元素
- bf.exists: 查询元素是否存在
- bf.madd: 批量添加元素
- bf.mexists: 批量查询元素
- bf.reserve: 创建布隆过滤器 bf.reserve key error_rate capacity ; 如果显示创建布隆过滤器,在调用add的时候会默认创建error_rate=0.01, capacity=100
注意:布隆过滤器capacity估计的过大,会浪费存储空间,估计的过小,会影响准确率,所以用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出估计值很多。 布隆过滤器的error_rate 越小,需要的存储空间就越大,对于不需要过于精确的场合,error_rate 设置稍大一点也无伤大雅。
布隆过滤器的原理
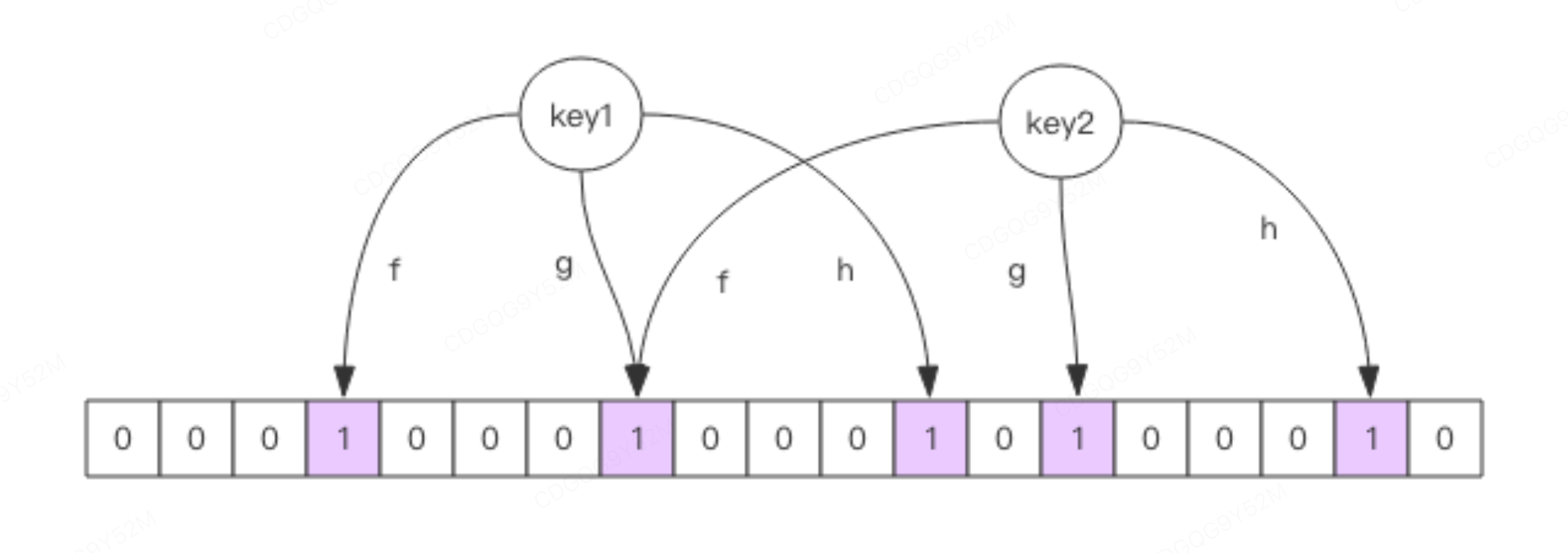
每个布隆过滤器都有一个大型的数组和几个不一样的hash函数
- 向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
- 向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都位 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在,如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这 些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低
在线空间占用估计工具: https://krisives.github.io/bloom-calculator/
原文链接: http://herman7z.site